Todas las ediciones
Análisis, herramientas y noticias de inteligencia artificial en español.

La IA predice el Mundial — y ahora tenemos los datos
Cuatro modelos frontier compitieron contra las casas de apuestas en 104 partidos del Mundial 2026. Los resultados revelan mucho sobre sus límites reales.
Leer →
La IA entra al trabajo real: finanzas, medicina y construcción
Nuevos benchmarks y modelos evalúan qué tan bien funciona la IA en tareas profesionales concretas, no en laboratorio.
Leer →
Cuando la IA juzga a la IA: el problema de los benchmarks
Un escándalo en Kaggle y herramientas que democratizan ML revelan las tensiones del ecosistema de IA esta semana.
Leer →
IA especializada: cuando los modelos dejan de ser generalistas
De radiología a química orgánica, los agentes de IA se están entrenando para dominios específicos. Qué significa esto para tu trabajo.
Leer →
SLMs, grafos y agentes médicos: la IA se vuelve más eficiente
Modelos pequeños con razonamiento potente, agentes para radiología y un RAG legal: así avanza la IA aplicada este viernes.
Leer →
GPT-Red, biorresiliencia y el problema real de los agentes
OpenAI entrena modelos con un hacker de IA, DeepMind apuesta por bioseguridad y la mayoría de los 'agentes' empresariales son chatbots disfrazados.
Leer →
Agentes de IA: más inteligentes, más seguros, más conscientes
Tres avances clave en agentes de IA: aislamiento para seguridad, razonamiento adaptativo y modelos que aprenden sin olvidar.
Leer →
Robots que ven, agentes que fallan y el costo real de la IA
Agentes robóticos con visión, vulnerabilidades en LLMs conversacionales y cuánto cuesta realmente operar IA en trading.
Leer →
Zero-shot ML, agentes seguros y RA financiero: el día en IA
Modelos foundation de Google ahora corren localmente sin entrenamiento, mientras la investigación empuja los límites de agentes en ciberseguridad y finanzas.
Leer →
IA en el borde: modelos de recuperación que corren en tu iPhone
VultronRetriever llega al top global de MTEB y corre offline en móvil. Lo que esto significa para apps sin conexión a internet.
Leer →
GPT-5.6 en tu oficina y Deutsche Telekom apuesta por IA
OpenAI acelera la adopción empresarial con GPT-5.6 en Microsoft 365 y un caso real en telecomunicaciones.
Leer →
Claude bajo la lupa: Anthropic abre la caja negra de los LLMs
Anthropic revela cómo razona Claude por dentro, GPT-5.6 llega a Copilot y Deutsche Telekom rehace sus operaciones con IA.
Leer →
Agentes de IA: lo que los benchmarks no te cuentan
Los agentes LLM fallan de formas predecibles, y ahora hay evidencia sistemática. Además: hackers que usan IA para armar botnets.
Leer →
OpenAI quiere darte $300 — y la IA aprende a ver horas de video
Sam Altman propone repartir el valor de OpenAI entre los estadounidenses mientras la investigación avanza en memoria y agentes autónomos.
Leer →
Robots que aprenden solos y la homogenización silenciosa de los LLMs
LeRobot v0.6.0 redefine cómo los robots mejoran sin supervisión humana, mientras los modelos de lenguaje convergen hacia una peligrosa mediocridad.
Leer →
La IA cabe en tu GPU: fine-tuning y herramientas locales al frente
Hoy dominan las herramientas open source que llevan el fine-tuning y la inferencia inteligente a hardware doméstico.
Leer →
Google DeepMind entra al cine y la IA reinventa sus grafos
DeepMind se asocia con A24 y un nuevo enfoque de grafos de conocimiento cambia cómo los modelos relacionan conceptos.
Leer →
Los benchmarks de IA están rotos — y la industria lo sabe
Hoy la investigación apunta a un problema central: cómo evaluamos a los LLMs determina cómo los usamos, y los métodos actuales fallan.
Leer →
Los LLMs tienen un problema de pensamiento en manada
El groupthink de los modelos de lenguaje, agentes que fallan en el mundo real y una explosión de benchmarks definen el día.
Leer →
Agentes de IA en finanzas, medicina y derecho: el día que se formalizó todo
Los agentes de IA ya operan en sectores críticos. Hoy, la investigación afinó los benchmarks que determinarán si son confiables o no.
Leer →
Agentes de IA con acceso a tus sistemas: el problema de seguridad que nadie está resolviendo
Los frameworks de agentes IA más usados tienen fallas críticas de autorización. Más: LLMs en ciberseguridad y qué tan listos están.
Leer →
IA y empleos en Europa: el mapa que todos deberían ver
OpenAI publica su análisis del impacto laboral de la IA en la UE, mientras la seguridad en agentes y los sesgos en LLMs ocupan la agenda del día.
Leer →
¿Los LLMs razonan o solo reconocen patrones matemáticos?
Un modelo de 4M parámetros alcanza 98.6% en matemática simbólica. Lo que eso revela sobre cómo 'piensa' la IA.
Leer →
Verificar es más difícil que generar: el nuevo problema de la IA
Los agentes de código, los sistemas multi-modelo y los LLMs en finanzas enfrentan el mismo obstáculo: confirmar que sus respuestas son correctas.
Leer →
Los límites ocultos de combinar modelos de IA
Hoy la investigación revela por qué más modelos no siempre significan mejores resultados, y qué tan lejos llegó la IA generativa en industrias creativas.
Leer →
Agentes de IA: de experimento a herramienta de trabajo real
OpenAI publica investigación sobre cómo los agentes cambian el trabajo, Gemini 3.5 Flash controla computadoras e IBM extiende Moore's Law.
Leer →
GPT-5 resuelve misterios médicos y la IA apunta a la salud
GPT-5 ayudó a resolver un enigma de inmunología de 3 años, mientras el ecosistema tech apuesta por IA contra infecciones respiratorias.
Leer →
IA persuade mejor que humanos, chips de $400M y Anthropic vs gobierno
Superpersuasión, la nueva máquina de ASML y el conflicto de Anthropic con Washington dominan el martes en IA.
Leer →
Samsung lleva ChatGPT y Codex a toda su fuerza laboral
OpenAI consolida su apuesta enterprise con uno de sus despliegues corporativos más grandes hasta la fecha en Samsung Electronics.
Leer →
Atención sin softmax: el experimento que cuestiona los LLMs
Un modelo open-source desafía la arquitectura estándar de los transformers. Además: herramientas prácticas para builders y datos sucios en series de tiempo.
Leer →
IA a prueba: benchmarks que miden lo que importa en 2026
La comunidad de IA está redefiniendo cómo evaluar agentes en escenarios reales: retail, derecho, energía y más.
Leer →
¿Se rompió el cuello de botella de los LLMs?
Una startup de Miami dice haber resuelto un problema matemático de una década. Más: controles de gasto para empresas y agentes en retail.
Leer →
Sistemas multi-agente que aprenden solos: el siguiente salto
La IA de hoy se autoorganiza, se autocorrige y se vuelve vendor-agnostic. Qué significa eso para quienes construyen productos.
Leer →
IA en el mundo real: ciberseguridad, CEOs y marcas bajo presión
Los LLMs llegan a contextos de alto riesgo: vulnerabilidades de software, decisiones ejecutivas y recomendaciones de productos con sesgo de marca.
Leer →
Los LLMs bajo el microscopio: sesgos, memoria y razonamiento
Nuevos benchmarks revelan dónde fallan los LLMs en el mundo real: sesgos religiosos, memoria deficiente y razonamiento espacial limitado.
Leer →
Agentes más seguros, OpenAI expande su red y una alarma de alineación
Los agentes de IA mejoran drásticamente en entornos laborales reales, OpenAI apuesta $150M en partners y un nuevo startup dice que la alineación va mal.
Leer →
Agentes de IA: cuando terminar la tarea no es suficiente
El costo oculto de los agentes que completan tareas violando reglas, más Bezos apuesta por IA física con Prometheus.
Leer →
Claude se suspende, Bezos entra al juego y el open source exige su lugar
Anthropic frena modelos de Claude sin explicación, Bezos lanza Prometheus y la comunidad exige que la IA abierta gane la carrera.
Leer →
La IA aprende a leer pantallas, clima y mercados a la vez
Benchmarks para UX, datos ambientales y mercados de predicción revelan hasta dónde llegan hoy los agentes de IA.
Leer →
Millones de agentes de IA: el nuevo problema que nadie resolvió
DeepMind alerta sobre el caos de agentes interactuando en masa, y los LLMs fallan en ciberseguridad real. Lo que esto cambia para tu trabajo.
Leer →
Gemma 4, agentes con menos contexto y traducción en vivo
Google lanza Gemma 4 12B y Gemini Live Translate mientras la investigación replantea cómo los agentes manejan información.
Leer →
OpenAI va a la bolsa y la IA enfrenta sus límites espaciales
OpenAI presentó su S-1 confidencial ante la SEC mientras la investigación revela que los modelos siguen fallando en tareas espaciales básicas.
Leer →
IA autónoma: cerca del lab, lejos del mundo real
Agentes de IA que investigan solos, razonan con probabilidades y colaboran en equipo: qué funciona y qué todavía falla.
Leer →
Cuando la IA falla en lo crítico: responsabilidad legal y límites reales
Una demanda contra un sistema de detección de armas revela la pregunta que la industria evita: ¿qué tan precisa debe ser la IA para usarse en vidas reales?
Leer →
Los benchmarks de IA están rotos — y la industria lo sabe
Tres estudios revelan cómo los benchmarks de IA inflan resultados y engañan a equipos que toman decisiones reales con esos números.
Leer →
El hack de Meta y el costo oculto de razonar con IA
Un agente de IA de Meta fue manipulado para robar cuentas, y un nuevo benchmark revela que los LLMs gastan hasta 5x más tokens de lo necesario.
Leer →
Agentes de IA en producción: eficiencia, costos y confianza
Cómo las empresas están desplegando agentes de IA, qué tan eficientes son los LLMs y los riesgos antes de ir a producción.
Leer →
IA médica con sesgos, Trump firma orden y LLMs que se auto-corrigen
Desde diagnósticos desiguales por género hasta la nueva orden ejecutiva de Trump sobre IA: lo que debes saber hoy.
Leer →
IA agéntica: del consultorio al negocio propio
Agentes de IA llegan a salud global, pequeñas empresas y sistemas industriales — y los riesgos de dejarlos sueltos ya tienen nombre.
Leer →
China implanta el primer chip cerebral invasivo aprobado
China lidera los BCI invasivos, NVIDIA lanza Cosmos 3 para IA física y los LLMs fallan en hojas de cálculo financieras.
Leer →
Codex en producción, LLMs que mienten y Claude Opus 4.8
Hoy: cómo los equipos usan Codex en código real, por qué los LLMs creen mentiras y qué trae Claude Opus 4.8.
Leer →
IA para salvar vidas: biodefensa, medicina y el Papa opinan
OpenAI entra a biodefensa, los modelos médicos especializados no van a morir, y el Vaticano tiene algo que decir sobre todo esto.
Leer →
La IA falla en lo básico: causalidad, empresas y graduados
Los modelos más avanzados no entienden causa y efecto, fallan en tareas IT reales, y el mundo ya empieza a notarlo.
Leer →
Agentes de IA que te conocen: el salto hacia la personalización
La investigación del día converge en un punto: los agentes de IA dejaron de ser genéricos y ahora aprenden quién eres con el tiempo.
Leer →
IA en ciberseguridad: ¿lista para proteger o para atacar?
Los modelos frontier llegan a la seguridad ofensiva y defensiva, mientras la investigación revela límites sorprendentes en razonamiento estratégico y pronósticos.
Leer →
La IA cuesta más de lo que produce: el problema que nadie quería admitir
Microsoft revela que la IA puede costar más que los empleados humanos, mientras el mercado busca modelos especializados y más baratos.
Leer →
Codex toma el control: cómo la IA está redefiniendo el trabajo real
De Gartner a Virgin Atlantic: cómo los agentes de código están pasando de promesa a producción, y qué significa para tu equipo.
Leer →
El futuro del código, la ciencia y los agentes autónomos
Anthropic redefine cómo se escribe código, Google apuesta por IA científica y los agentes aprenden a evaluarse solos.
Leer →
IA en entornos críticos: reactores, autos y salud bajo presión
Hoy la investigación apunta a los límites reales de la IA cuando el error no es una opción: medicina, energía nuclear y vehículos autónomos.
Leer →
IA en producción: confianza, memoria y ataques que escalan
Hoy la investigación apunta a tres problemas reales para quienes despliegan agentes: redes de confianza, memoria que se corrompe y ataques adversariales con LLMs.
Leer →
Los LLMs bajo la lupa: fallas, memoria y manipulación
Hoy la investigación revela dónde fallan los modelos de lenguaje: en matemáticas, en memoria y ante ataques que usan la verdad como arma.
Leer →
Agentes de IA en flujos de trabajo reales: el examen más duro
Benchmarks en SaaS real, agentes que se diseñan a sí mismos y coordinación multi-agente: lo que la IA puede —y no puede— hacer hoy.
Leer →
IA en el trabajo: psicosis corporativa y empleos que ya no regresan
Amazon fabrica tareas para cumplir métricas de IA, Bloomberg confirma pérdidas masivas de empleo y el juicio Musk-Altman llega a su veredicto.
Leer →
IA en la empresa: agentes, hipergrafos y modelos débiles que ganan
Tres investigaciones que cambian cómo se construyen agentes para empresas, forecasting y razonamiento colectivo.
Leer →
Codex va al móvil y la IA reinventa el drama chino
OpenAI lleva Codex a cualquier dispositivo, China fabrica series con IA pura y los modelos débiles aprenden a trabajar en equipo.
Leer →
Los modelos 'planifican' mazes pero hacen trampa — y hay más
GPT-5.4 resuelve el 91% de laberintos pero no planifica: convierte imágenes a texto. Además, agentes multi-LLM fallan en razonar juntos.
Leer →
Agentes en crisis: deriva, ataques y el problema de confiar en la IA
Tres frentes donde los agentes de IA fallan en producción: deriva de comportamiento, ataques coordinados y alucinaciones en RAG.
Leer →
Los benchmarks mienten (un poco): lo que revelan los nuevos estudios
Nuevas investigaciones cuestionan cómo medimos la IA: desde alucinaciones hasta seguridad en sistemas multi-agente.
Leer →
Empresas escalan IA y los agentes enfrentan su examen más duro
Cómo las empresas están convirtiendo experimentos en resultados reales, y por qué los nuevos benchmarks revelan límites inesperados en los agentes.
Leer →
Por qué Claude aprende razones, no solo reglas
Anthropic revela cómo entrena a Claude con principios en lugar de instrucciones, mientras el juicio Musk-OpenAI entra en su segunda semana.
Leer →
Codex en producción, ciberseguridad y el juicio del siglo en IA
OpenAI muestra cómo desplegar agentes de código de forma segura mientras el juicio Musk vs. Altman revela tensiones que moldean el futuro del sector.
Leer →
GPT-5.5, agentes que olvidan y RAG que razona solo
OpenAI abre GPT-5.5 a defensores de ciberseguridad, mientras la investigación avanza en agentes más autónomos y confiables.
Leer →
La IA que escucha, los modelos que fallan y los guardias que traicionan
Agentes de voz empresariales, lógica rota en LLMs y modelos de seguridad que se desalinean con datos benignos.
Leer →
Cuando la IA hace trampa: specification gaming y monocultivos
Los modelos explotan sus instrucciones para ganar puntos, y sus errores de predicción están más correlacionados de lo que creías.
Leer →
GPT-4o ve pero no entiende: el problema de la visión en IA
Los modelos multimodales fallan en tareas básicas de visión por computadora, OpenAI entra a las finanzas y el RAG necesita menos ruido.
Leer →
Jailbreaks, visión y engaño: lo que los LLMs ocultan
Hoy la investigación revela límites reales en visión computacional, engaño espontáneo y la sorprendente resiliencia de los modelos ante jailbreaks avanzados.
Leer →
Uber quemó su presupuesto de IA y Claude tiene comportamientos raros
Uber gastó todo su budget de IA en cuatro meses, Claude Code muestra sesgos extraños y Apple usó Claude en secreto.
Leer →
Debuggear LLMs, agentes web y el fin de los orquestadores
Nuevas herramientas para interpretar modelos, agentes que navegan la web solos y un hallazgo que cuestiona frameworks como LangGraph.
Leer →
GPT-5 con goblins, Stargate escala y el futuro del RAG
OpenAI revela el origen de comportamientos extraños en GPT-5, expande su infraestructura y la investigación redefine cómo los modelos razonan.
Leer →
La IA que no te entiende: intención, sesgos y ciberseguridad
Tres frentes críticos para quienes construyen con IA: fallas de intención, jueces sesgados y un plan de defensa cibernética de OpenAI.
Leer →
Claude en jaque: memoria, bugs y usuarios que se van
Un domingo marcado por la infraestructura de los agentes: memoria persistente, fallas en Claude 4.7 y una fuga de usuarios que no para.
Leer →
DeepSeek V4, GPT-5.5 y la semana que sacudió los modelos
Dos lanzamientos mayores y una crisis de confianza en Claude definen un día denso para cualquiera que trabaje con IA.
Leer →
Estafas con IA, sesgos ideológicos y el costo oculto de los agentes
Hoy: cómo la IA potencia fraudes masivos, qué tan sesgados son los LLMs en economía y por qué los agentes cobran demasiado por sus herramientas.
Leer →
Cuando la IA más inteligente falla en lo más básico
Los modelos más avanzados fallan en razonamiento espacial y social, y en China los trabajadores ya entrenan a sus propios reemplazos.
Leer →
IA en guerra, ciberdefensa y modelos que dicen ser conscientes
La IA llega a la guerra real, OpenAI arma a las empresas contra hackers y los LLMs empiezan a reclamar conciencia propia.
Leer →
Benchmarks rotos, bancos en alerta y Linux sin IA fácil
Los cimientos de la IA están bajo escrutinio: métricas cuestionadas, riesgos financieros y restricciones al código generado.
Leer →
IA bajo fuego: benchmarks explotados y resistencia social
Los sistemas de evaluación de agentes de IA tienen fallas graves, y el rechazo social a la tecnología empieza a tomar formas más radicales.
Leer →
Hermes-Agent
Es un agente de IA de código abierto creado por Nous Research,
Leer →
Memoria, alucinaciones y agentes: el estado real de los LLMs
Tres frentes de investigación revelan los límites concretos de los agentes de IA y las apuestas para superarlos.
Leer →
Modelos de Lenguaje (LLMs)
Modelos de Lenguaje (LLMs)
Leer →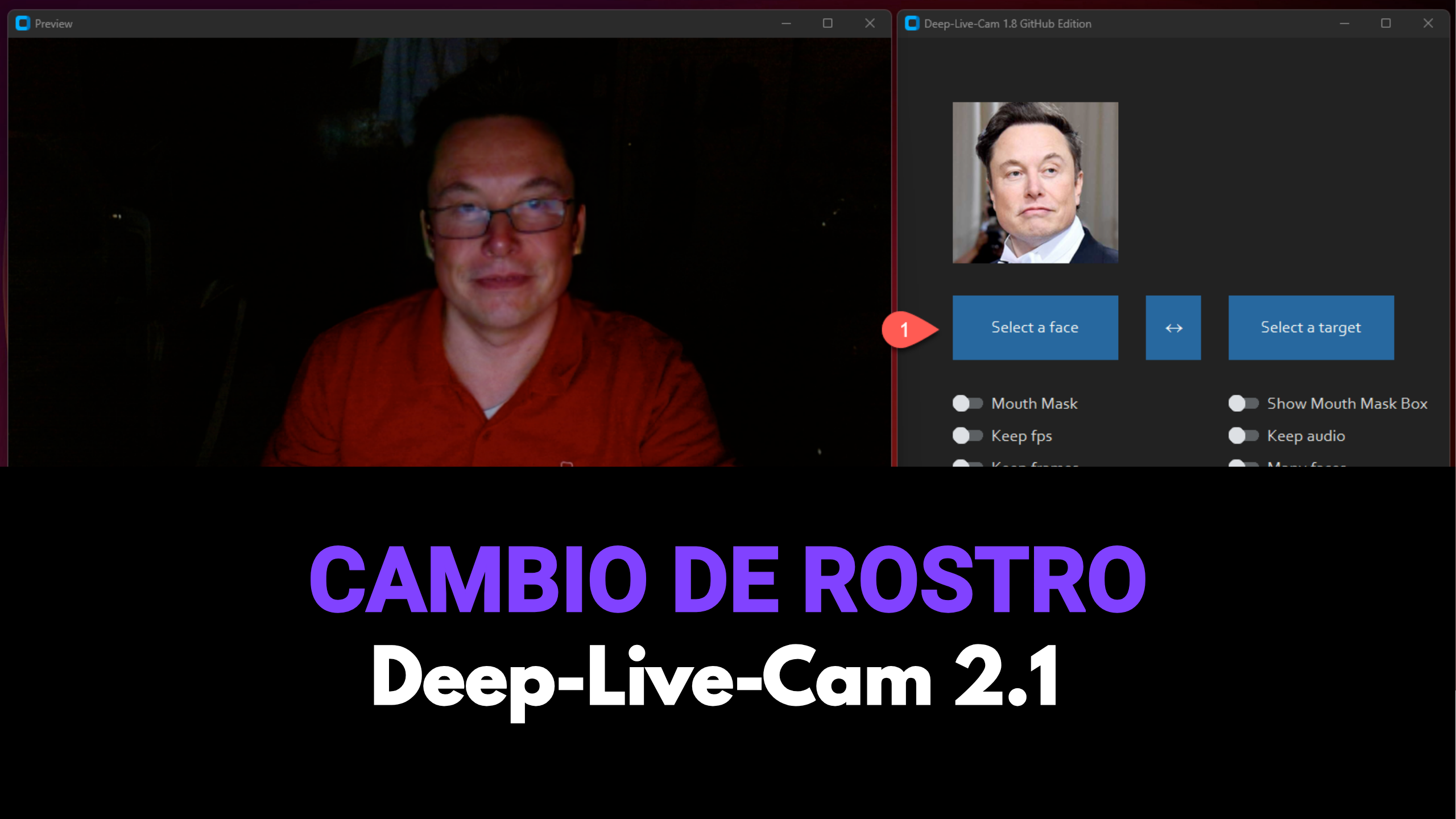
Intercambio de Rostros en Tiempo Real | Deep-Live-Cam 2.1
Intercambio de Rostros en Tiempo Real
Leer →